Create a New Dataset¶
Aunsight users can easily create new dataset records and specify options for those datasets using the Aunsight dataset workspace. This article describes the process of creating a new record and explains the various options that users may wish to specify when they create datasets.
Basic Steps¶
After logging in to the Web interface and selecting the relevant context you wish to work in, go to the Datasets workspace by clicking the Datasets icon (![]() ) in the palette on the right.
) in the palette on the right.
From the list displayed on the left of the main view, click the plus button (![]() ) to open a dialog for creating a new dataset.
) to open a dialog for creating a new dataset.
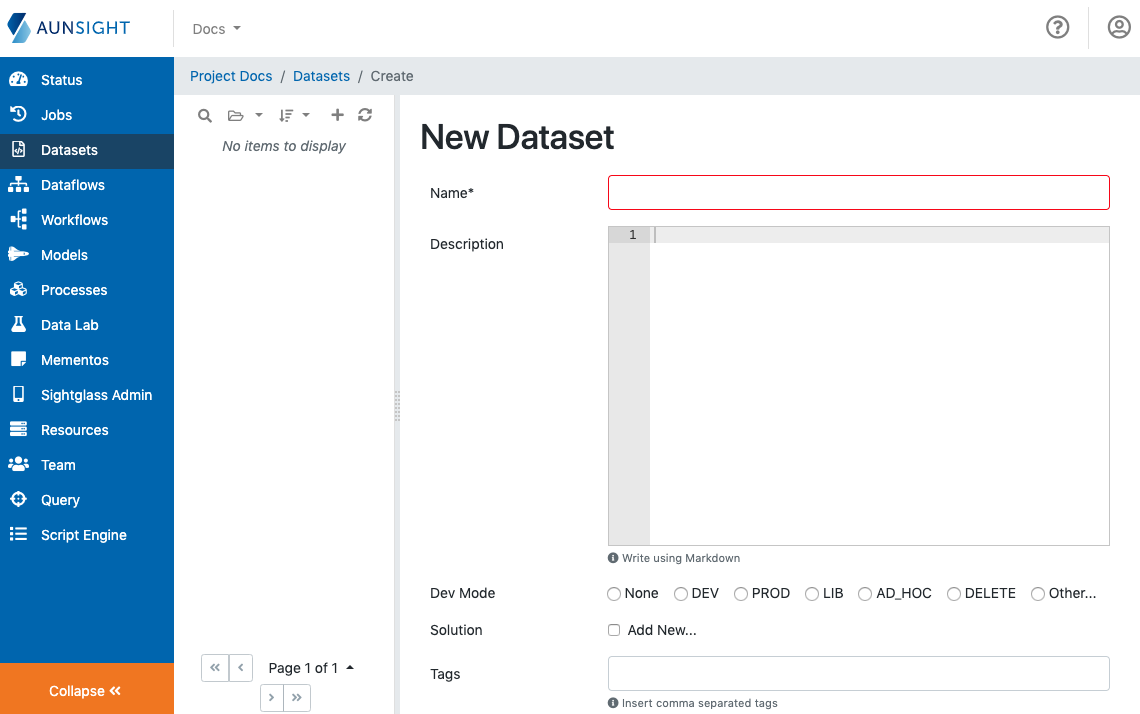
To create a dataset, the only required field is the name for the new dataset record. Aunsight will populate all the other options with default values.
In most cases, you may wish to specify more options than this. The remainder of this article describes these options in greater detail.
New Dataset Options¶
Though datasets can be created by declaring just a name, there are many options to consider when doing so. It is important to understand these advanced options, as many cannot be modified once a dataset is created.
Description¶
The description field is a plain text field that will be used to generate the dataset's description text. Though the field accepts only plain text, it will render markdown formatting as its output. Unlike most other options, the description field can be edited at any time after the dataset is created.
Tagging¶
Aunsight datasets can be tagged with a variety of flags that allow users to organize and structure their datasets. Unlike most other options, tags can be changed at any time by editing them via the details tab in the datasets workspace.
DEV Mode¶
Dev mode tags are used by solutions architects to describe specific uses for the dataset you are creating. For example, a "DEV" tag usually means the creator of this dataset did so as part of a solution development process, whereas the "PROD" tag signifies a dataset is part of an ongoing production data solution delivered to data consumers. Use of these tags for specific purposes is not enforced, but teams should work together to be consistent in their use of this nomenclature.
Solutions¶
Solutions are custom tags (32 character limit) denoting that a dataset relates to a particular data solution. For example, the datasets that store the input and outputs for a predictive model that forecasts retail sales would both be tagged for the "Retail Sales Forecast" solution. Datasets may also be tagged for more than one solution. For example, a dataset that contains a company's customer mailing list might be used for multiple data solutions and can be tagged for each of these.
Custom Tags¶
In addition to the standard tags, Aunsight datasets can also be free-form tagged by adding keywords as a comma separated list of tags (32 character limit per tag).
Choosing Data Format¶
Aunsight supports storing data in any number of storage formats. Users should select the format that reflects the source of their data. A mismatch between the source format and the Atlas record's data format attributes can lead to unpredictable results.
Attention
The data format for a dataset cannot be changed. Once set, data will remain in this form.
Aunsight datasets support the following delimiter and data formats:
- CSV - Comma separated values (
,) - DSV - Delimiter separated values (Any character specified)
- LDJSON - Linked-data JSON
- PARQUET - Column-oriented file format
- PSV - Pipe separated values (
|) - TSV - Tab separated values (
\t)
In addition to the field delimiters, Aunsight can interpret both Windows (\r\n) and MacOS/Linux row (\n) delimiters. Using the wrong row delimiter can lead Aunsight to interpret the data as a single row.
Resource¶
Aunsight datasets are actually metadata records so the dataset does not store actual data, but merely catalogs and tracks data being managed by the underlying storage infrastructure. For this reason, storage resource are defined on the dataset. Storage resources are physical assets like a Hadoop cluster in a data center that are represented in the Aunsight platform by resource records. When creating a dataset, a default resource is set based on the organization or project level default resource configurations. However, users may select an alternate resource to store the dataset on from the drop-down menu which is populated based on the storage resources available to the dataset's owning context.
Custom Path¶
As with the storage resource, datasets include metadata about the file used to store data on a resource. Normally, Aunsight will create a file using the dataset ID as its file path. Setting a custom path value will allow you to specify the filename used by the underlying storage resource. When specifying a custom path, any string that meets the requirements for a valid filename on the target filesystem and operating system can be used (e.g. avoid special characters like /, \, *, [, ], :, ;, | ,).
Bear in mind that Aunsight does not enforce unique filenames for each dataset. It is possible to create multiple datasets (Atlas records) that are pointing to the same file on a storage resource. In this case, both datasets would be operating on the same data, but they could have different metadata to allow two different schemas. While this can be useful in some few cases, unpredictable results can occur when multiple datasets are reading and writing from the same file. Additionally, using the same file path for two datasets increases the risk that file locks will cause dataflow or workflow failure if both datasets attempt to perform actions at the same time.
Caution
Aunsight does not enforce unique filenames for each dataset. Unpredictable results can occur when multiple datasets read and write from the same file.
Add Schema¶
The schema option allows users to add a schema by entering raw JSON at the time of Atlas record creation. This can be particularly useful if you wish to create a new dataset using a data source whose schema is already used somewhere else. Simply copy the schema from that dataset as JSON and paste it into the new dataset. Alternately, you can skip this step and create schema later using the Aunsight schema tools.
Upload file¶
If you wish to immediately ingest data into your new dataset, you can do so by uploading a source file at dataset creation. Simply click the "Upload File" checkbox and a file selector input will appear. Use the input to specify the file and it will be uploaded and ingested as soon as the dataset record is created. You can also skip this step and ingest data into your dataset later.
Note that if you do not upload a file at the time of dataset creation, Aunsight will create an Atlas dataset record, but no file will be created on the underlying storage resource. This is because Aunsight manages storage resources 'lazily,' meaning that hardware resources only execute the operations requested when output is required. This is generally a positive feature as it decreases unnecessary hardware utilization, but it in some cases it can complicate the migration of data since files may not exist on the underlying hardware until an ingest operation causes the creation of a new file.